Everybody, eventually
A company can do lab things, and a lab can do company things.
But the mechanics of distributing ideas are different. A company validates their ideas in the market, with a product. A lab validates their ideas with continued research.
I spent 2019-2024 working on 'companies' that were poorly disguised labs. Mostly with Kristo.
These were companies with products 100% dependent on research happening first.
Kiri (2019): Transformer chatbots and search
This was well before ChatGPT; we got started before GPT-2 released. It started as a customer service helpdesk that Kristo was using to manage emails for his ecommerce business.
We were setting up language model-backed automation; customer sends an email, model would classify it, find a relevant answer in the knowledge base, and suggest a template response.
It quickly became obvious that these models would become the core for a new class of software.
They were still small, too dumb to have a conversation over long context. But surely, that could be solved with some training and engineering. We brought on our friends, Ramon and Cameron. And we did just that.
RAG didn't have a name at the time, and we didn't give it one. It was just the 'engineering' answer to enhancing model capabilities without a ton of compute. In my mind, we weren't doing research to define a product category; we had a product and we were improving it.
Directionally, the research and product ergonomics were in line with what the future would hold. But we shared the work as demos of a product that was not ready.
So, we'd explain to VCs:
- This tech is nascent
- We can improve it in these ways
- If we do that, it will be everywhere
And they saw a company talking about a product that sort of worked, with zero users and no revenue.
We bridged the wrong capability gap for the time. It was worthy of a paper when we did it, but the product we were pushing demanded base models that didn't exist yet.
Backprop (2021): distributed inference + compute markets
Compute was a bottleneck. We didn't have the resources to push the boundaries of scaling laws ourselves. We had to train models, and we had to run inference.
The space had grown since we started Kiri. For it to continue thriving, compute would be king. Training and inference weren't "us" problems, they were the industry itself.
Kristo and I built four servers, each with four 3090 cards. We set them up in my apartment for the first few months; my electricity bill 10x'd, my apartment was hot, and they were loud.
We built out an easy-to-use finetuning library, which could hook into our GPU cloud. We made it easy to upload your trained model and deploy it via API.
The vision was, in time, to develop a market-making firm for compute: a pool of resources, available on-demand, for training or inference. And the library was to make it easy to distribute and perform work using those resources.
We earned some revenue, but the explosive need for compute wouldn't hit for a few years.
Backprop itself had the capabilities it needed to deliver on its premise. But there was a demand gap. People were finetuning language models, but there wasn't much practical inference happening at scale.
Before that could happen, models needed to be capable of doing valuable work.
Agentsy (2023): Agent harness + context management
The release of ChatGPT validated those years of work on the fringe; scaling was working, model capabilities were increasing rapidly, and the number of AI startups boomed.
But by the time ChatGPT came out, we were utterly bored by chatbots.
The frontier was, as I said in the Kiri section, building a new class of software around this smart processor. Jamming a chatbot into a regular piece of software wasn't the future.
The models were good enough to execute on something that was impossible when we started.
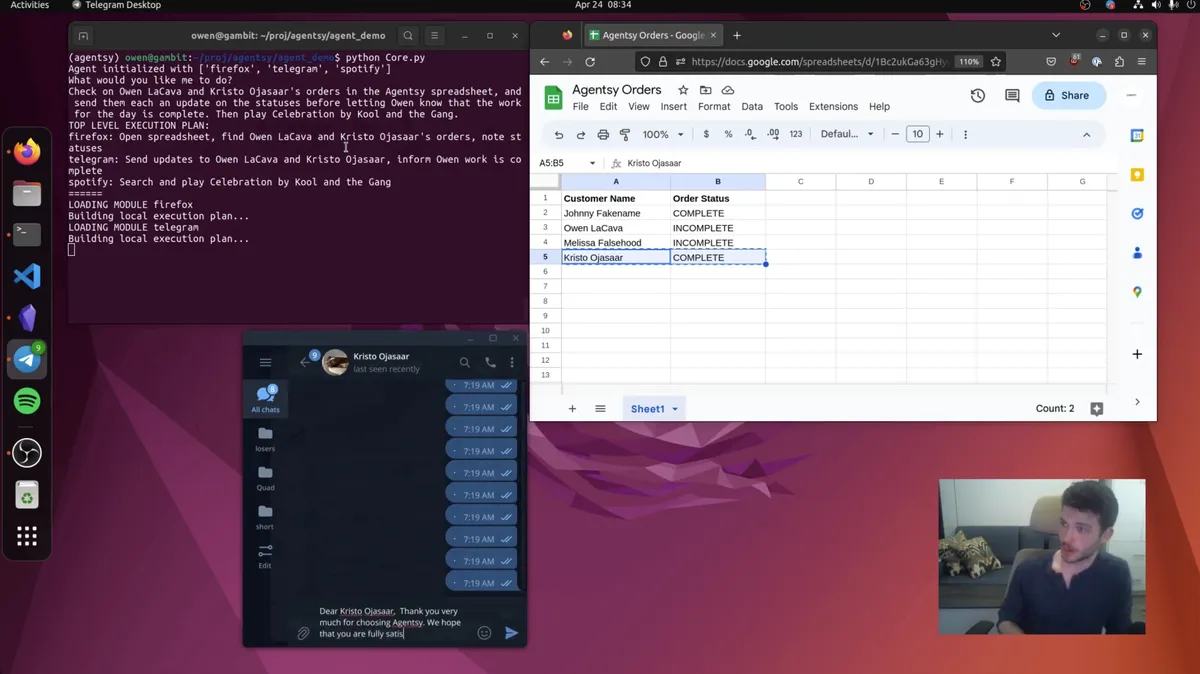
My first love in AI was reinforcement learning: agents learning from their environment. I wanted to build a harness, agnostic to the model layer, and equip it with tools, memory, and identity.
The pattern was generic; a smart model, with the right tools, and good context management, could feasibly do anything on a computer. And context management was just another tool models could learn to wield!
It'd make models capable of doing real work. Which would be pivotal to establishing a compute market. Inevitable.
Kristo was there for the beginning of Agentsy, but later split off, and I continued.
Initially, "JSON output" for these models was done with instructions, schema examples, and parsing-with-retries. It sucked, and I felt strong typing was an essential for cognitive systems, so I spent time on that first.
Grammar-based guided decoding in Llama models, then a thin typing wrapper to turn arbitrary python classes or function signatures into grammars for decoding.
(Check out DSPy - a better/evolved version of the patterns).
Wider Agent discourse opened on stuff like BabyAGI, which was novel but not useful. The word "Agent" started getting used by every company shoving a language model into their software. The space had gotten noisy.
It was similar to Kiri's situation. Reasoning models were nigh. Thanks to the developments of preceding years, people were more open to the idea of "capable AI" than they were in ~2020, but the abstraction made it a tough pitch.
Feedback on Agentsy was, largely, "who are the users?".
"Everybody, eventually" wasn't sufficient, because that means "today, nobody".
Agentsy failed because of positioning.
bitStudio (Today)
After Agentsy, Kristo and I began kicking new ideas around.
As expected, every idea hinged on some form of novel work.
The only difference was agreeing that we'd build something useful immediately, and earn revenue to support the work that'd make it more useful over time.
We landed on virtual fitting rooms, for fashion brands. Let shoppers try on clothes virtually, like they would in a brick-and-mortar store. "Virtual try-on" was doable with some training. It wasn't perfect, but it was consistent enough to gain traction.
To do it at scale, we needed better models and faster inference. Novel work, but highly focused.
We used the same servers we built for Backprop as our compute bootstrap. The GPUs were a few years old, but those limitations fed the exact loop our product needed: we had to train small, fast models that were really good at try-on.
General editing models like Nano Banana weren't around. Their release has launched countless competitors.

But our inference is much faster, so our costs are lower. Our quality is better. And the product is carefully designed, with active feedback from users that are paying for it.
Kiri, Backprop, Agentsy - we built lab artifacts, and we knew the shape products building on it would eventually take. Our goal was to build something that we knew would exist in the future. Then we tried to validate our thinking on those product shapes alone, instead of first convincing the world that the technology underlying them was inevitable, too.
bitStudio is a company, and we do some lab things. We picked a direction where capability was sufficient, demand existed, and positioning was niche. The novel work compounds a product that works, instead of preceding it.
The revenue we have today was a decision.